
小编:alc浏览:10572021-11-24 10:16:45
昨晚研究了百度下拉框的问题,得到的数据是jquery加载的,如下。
请求地址和Agent都很容易完成,就是这个返回数据有点麻烦。然而,在自己的琢磨下,也解决了,但我有一种感觉,我的方法并非最好的,先分享一下,如果你有更好的方法,可以和我分享一下。
我主要用正则表达式截取。
从获得的数据来看,有用的数据在一对中括号内。
所以这样做很容易,我直接用正则表达式,取中括号内的内容。
规则如下:
reg='[[](.*)[]]'
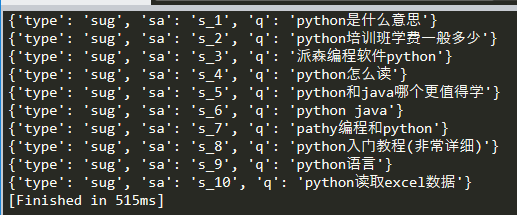
之后,我得到了一个包含多个字典数据的列表。这种数据不能直接使用json.loads()方法。
仔细看了一下,这个列表里有很多字典数据,那么从这个列表里一个个还原这些字典数据有什么好办法呢?
所以我想到了eval()这个函数,这个函数可以让字符串运行,可以让它恢复真实的身体。
将处理过的数据,再用此函数处理,顿时清爽,全成字典数据。
像下面这样。
# -*- coding:utf-8 -*- #! python2 import requests import re url='数据网址' header={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)\ AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36' } reg='[[](.*)[]]' #正则表达式 r=requests.get(url,headers=header) #发送get请求 data2=re.findall(reg,r.text) #用正则表达式取数据,返回数据为列表型 #print(data2) #print(type(data2)) if data2: k=eval(data2[0]) #用eval()函数将字符串恢复真身为字典 for i in k: print(i) else: print('没有数据')
大功告成。








